具体と抽象、少林寺拳法のリーダー教育に関する雑記
私は学生時代に少林寺拳法を護身術として始め、社会人になってから再開し、今も続けています。 一方で、仕事では「具体と抽象」を意識する場面が多くあります。そんな中、趣味として続けている少林寺拳法と仕事上の学びが結びつく瞬間があったので、ここに記録しておきます。
きっかけ
少林寺拳法の競技では、基本的に「演武」が中心です。演武とは2人1組で少林寺拳法の技を組み合わせ、技術や武的要素を競うもの。殺陣のようなイメージに近いですが、審判による評価が点数として現れ、合計点を競います。
私自身、護身術としての側面には関心があるものの、演武への熱意は正直高くありませんでした。また、上手な有段者たちの演武を目にすると「自分には無理だ」と感じることが多く、結果として演武が得意ではありません。
ところが段位を取得している以上、演武の指導役を求められることがありました。しかし、演武で高い点数を目指す人たちに対し、私が指導できることは少なく、むしろ指導すること自体が彼らにとってマイナスになるのではないかと悩みました。
ここから次の問いが浮かび上がりました。
自分より優秀な人たちを率いなければならないとき、自分はどう振る舞うべきか?
視座を上げる
「演武の点数を上げる」という具体的な目標を達成するのが難しいと感じた私は、一度視座を上げ、少林寺拳法の本質的な目的に立ち返ることにしました。
少林寺拳法は護身術であると同時に、「社会のリーダーを育成する」ことを目的としています。演武や大会も、その目的を達成するための手段の一つであるはずです。
演武を「リーダー育成」という観点で捉え直せば、自分にできることが見つかるかもしれません。そして、それは私自身の学びにもつながると感じました。
リーダーに求められる能力
リーダーに求められる能力として以下があると考えます。
- 理想や目標を明確に設定する能力
- 抽象的な目標を具体的な行動計画に落とし込む能力
これらはリーダーに限らず、さまざまな場面で重要なスキルです。この観点を基にすると、「社会のリーダーを育てる」という抽象的な目標を以下のように具体化できます。
- 理想や目標を明確に設定する能力を育てる。
- 設定した目標を達成するために具体的な行動計画に落とし込む能力を育てる。
少林寺拳法の演武とリーダーに求められる能力の紐付け
通常、指導者が演武者に対し「ここをこうしたほうが良い」とアドバイスを行いますが、リーダー育成の観点では異なります。まず、演武者自身に「理想の演武」について考えさせることが重要です。
演武者が「理想」を明確にできなければ、次の質問を投げかけます。
- 「理想の演武」を定義するために、どんな情報が必要か?
- 必要な情報を得るには、どう行動すべきか?
こうしたプロセスを通じて、演武者に理想を定める力を養ってもらいます。
- 抽象的な目標を具体的な行動に落とし込む
理想が定まったら、次はそのギャップを埋めるプロセスを設計します。体育会系の「ひたすら練習!」ではなく、理想と現実を埋めるための最適な練習方法を考えることを重視します。さらに、練習方法を仲間と共有し、周囲を巻き込むことで、リーダーとしての資質が育まれます。
おわりに
少林寺拳法を通じて「具体と抽象」の行き来を考えることは、仕事や日常生活にも通じる深い学びがあります。今回は、取り留めのないメモとなりましたが、自分の経験が誰かの参考になれば幸いです。
WebStormでDenoを利用するときのメモ
プラグインのインストールは以下のリンクの通り。
Set Up Your Environment | Deno Docs
WebStormでDenoのサポートを有効にするにはSettings > Language & Frameworks > Deno > Enable Deno support for this project を on にする必要があるみたい。


Read, Write モード. クラスにモードを取り入れ、利用できるメソッドを制限する 〜クラス設計メモ
概略
- 集約やEntityのような、状態変更のあるモデルを参照系で利用する際に、状態変更を起こすメソッドを呼び出せてしまうのが気になる
- 参照系のユースケースの際や、計算用のモデルに集約を渡す際には同じモデルを参照用途のみで利用できるようにしたい
- generalized typed constraint を利用して、状態変更のあるモデルに
Readモード,Writeモードを導入する
本文
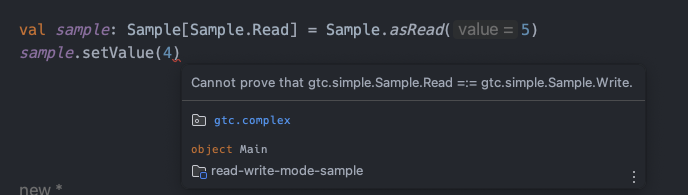
実務では使ったことはないのですが、ちょっとしたアイデアとして考えてみようと思います。 やりたいイメージとしては、更新可能なモデルに対して、ReadモードとWriteモードを定義し、Writeモードの時だけ更新メソッドを呼べるようにしたいといった感じです。
まずは Mode を定義します。
これと generalized typed constraints を利用して実現します。 ものすごくシンプルに作るとこんな感じですね。
型パラメータに Mode を受け取っています。M が Write の時のみ、setValue メソッドは呼び出せます。
Read モードの時に setValue メソッドを呼ぼうとすると、コンパイルエラーになります。
今回の例はシンプルなものでしたが、モードを使うことで不用意に呼び出せなくする方法を考えてみました。 個人的には結構面白いなと思いつつ、そんな不用意に更新しちゃう人いないよなという気もしてるので冗長な気もしてます。
Mac mini & Starship で [WARN] - (starship::modules::battery): Unable to access battery information: AppleRawMaxCapacity
会社の人のおすすめで最近Starshipを入れました。private の Mac mini でも同じの入れたけど、以下の状況に遭遇しました。
Last login: Fri Sep 8 12:49:26 on console [WARN] - (starship::modules::battery): Unable to access battery information: AppleRawMaxCapacity
バッテリー関連の機能にアクセスしようとしているようですが、mac mini にバッテリーはないからwarningが出てしまってるのかな?
Startshipの設定ドキュメントを見ると、以下の package を battery とかにしたらいけそう?
# Disable the package module, hiding it from the prompt completely [package] disabled = true
というわけで以下のようにしたら直りました。
[battery] disabled = true
スプリントの達成確率を雑に計算する
本題
現職ではスクラムなる開発プロセスを実施しています。スクラムではPBI(Product Backlog Item)という単位にやることが切り分けられ、それらの見積もりにストーリーポイントを利用します。ストーリーポイントはPBIの大きさを測る指標と言われており、大体開発者の所感で決まります。1, 2, 3, 5, 8, 13, 21,...とフィボナッチ数列で表すパターンが変われることが多く、数字が大きくなるほど、重く不確実なPBIとなります。
しばらく開発していて、ストーリーポイントの合計が10で同じでも、5 * 2 の 10 と、2 * 5 の 10では全然重さ違くない・・・?という話がチーム内で出ました。 ぶっちゃけ前者の方が圧倒的に重いです。後者は意外と楽。
そこで、ストーリーポイントのタスクが完了する時間を確率変数としたときに、その従う分布はストーリポイントごとに異なるのではないか?と考えました。
そう考えるのであれば、あるストーリーポイントの確率変数 が従う分布がわかるもしくは仮定すれば、これまでの実績から大体どれくらいの時間でスプリントが終わるのか推測できるのでは?とも。
まずはストーリーポイントごとの完了までにかかる時間を確率変数とし、それぞれ、 とします。確率変数
はそれぞれ確率分布
に従うとします。
例えば、ストーリーポイント5のPBIが40時間以内に終わる確率は
と表現されます。
スプリントは複数のPBIで構成されます。これまでの経験からベロシティが大体10くらいだと分かってるとしましょう。この場合例えばストーリーポイント2, 3, 5で合計10になる3つのPBIをこのスプリントでやろうという話になります。つまり、このスプリントのおける全てのPBIが完了するまでの時間の確率変数Tは
のように表現できます。ここで、確率変数の和について考えますが、一般的なものは以下のようになるので扱うのはちょっと難度が高そうです。。
2つの確率変数 に対して、その和
の分布は
であり(途中式は省略)、確率密度関数は
ここは一旦、確率変数 はそれぞれ独立かつ正規分布に従うと雑に仮定しましょう。
※実際はもうちょっとズレた分布に従ってそうですが実務で問題になることはまだないでしょう。多分。
独立した正規分布を仮定すると再生性という特徴があります。
つまり
かつ、 と
が互いに独立である時、確率変数
は正規分布
に従う
というものです。これを仮定してあげれば平均と分散だけわかっていれば、あとは逆関数(Google Spread Sheet だと NORMINV)で例えば90%の確率で終わるまでにかかる時間が計算できるようになります。
例えばこれまでの実績からストーリーポイントと平均、分散の値が以下のようだったとします。
| SP | 平均値 | 分散 |
|---|---|---|
| 2 | 6.5 | 7.3 |
| 3 | 14.2 | 10.0 |
| 5 | 30.5 | 22.4 |
この時、SPが2, 3, 5 のチケットで構成されたストーリーポイント10のスプリントは となり、
となります。
また、SP5のチケット2つで構成されたストーリーポイント10のスプリントは
となり、
となります。
よって90%の確率で終わるのにかかる時間はそれぞれ計算してあげると、約59時間、69時間となります。 まあ適当に作ったデータですが、SPが上がるにつれて分散が上がるのは所感通りですし、SPが多いチケットでスプリントが構成されると達成が困難になるのも所管通りなので使えそうな気がします。
このように、各ストーリーポイントの達成にかかる時間を確率変数として定義し、それぞれ独立した正規分布に従うと仮定すれば、どれくらいの時間、どれくらいの確率でスプリントが達成できるかが予想できそうです。
今度社内でも試してみようと思います。
久々の統計でテンション上がりました。色々忘れてるな。。
追記
実際の分布は対数正規またはベータ分布に従うそう。
おー、先日に話してたやつ。いいっすね(ベータ分布か対数正規分布になりそうかも)https://t.co/UDzbLS5hyF
— 田所 駿佑 | Shunsuke Tadokoro (@todokr) 2023年3月19日
対数正規分布やベータ分布は再生性を持たないから上記のようなことはできないのが実用上の難点。。 対数正規分布を正規分布に変数変換してあげればいけるかも?とちょっとだけ思った。
個人的におすすめなドメインサービスの書き方
DDDの実装パターンでドメインサービスがあります。 ドメインサービスは、集約や値オブジェクト、エンティティでは扱えない操作を代わりにやる「その他」的なポジションで、ベスプラ的な実装方法がないように思います。ここでは、例としてイメージしやすいメールアドレスがユニークであることをチェックするドメインサービスを例に、よくある実装と、そのペインを確認し、ありたい姿を示した後、最後にその解決策として、ドメインサービスからエンティティへメッセージを送るようにする実装を示します。
扱う例
ここでは、例としてシンプルな、ユーザーのメールアドレスを変更するというユースケースを扱います。
- ストーリー: ユーザーは自身のメールアドレスを変更することができる
- 制約: メールアドレスはシステム内で一意である必要がある
処理の流れとしては以下のようになるでしょう。
- ユーザーは、メールアドレスの変更をシステムにリクエストする
- システムは、リクエストされたメールアドレスがユニークであるかどうかをチェックする
- メールアドレスがユニークであれば、Userオブジェクトのemailの値を、リクエストした値に書き換えて保存する
よくある実装
まずは User オブジェクトにメールアドレスを変更するメソッドを定義していきます。
final class User( id: UserId, name: Option[String], email: EmailAddress ) extends Entity[UserId] with Aggregate { // メールアドレスを変更するメソッド // ここで引数で渡されたメールアドレスがユニークかどうかは判断できないので、 // 暗黙的にドメインサービスを経由したことを期待している def changeEmail(email: EmailAddress) = copy(email = email) private def copy(...) = { ... } }
次に、メールアドレスがユニークであることを検証するドメインサービスを準備します。詳細な実装は重要ではないため、ここでは省きます。
trait UserEmailUniqueChecker extends DomainService { /** * 引数のメールアドレスがユニークであるかどうかを調べる */ def check(email: EmailAddress): Boolean }
この二つを用いて、ユースケースでこの仕様を実現するのが一番簡易的でよくある実装かと思います。
class ChangeEmailUseCase @Inject() ( userRepository: UserRepository, userEmailUniqueChecker: UserEmailUniqueChecker ) { import ChangeUserEmailOutput._ def handle(input: ChangeUserEmailInput): ChangeUserEmailOutput = { val result = for { // 入力されたユーザーが存在するか? user <- userRepository.findBy(input.userId).toRight(NotFoundUser(input.userId)) // 入力されたメールアドレスはユニークか? _ <- Either.cond(userEmailUniqueChecker.check(input.email), (), EmailIsNotUnique(input.email)) } yield { val emailChangedUser = user.changeEmail(input.email) userRepository.update(emailChangedUser) Success(emailChangedUser) } result.merge } }
全体像
この実装のペインは何か?
よくある実装の大きなペインは以下の2つです。
- エンティティの状態変更の際に仕様上必要なバリデーションのありかが、Entityのメソッドからわからない。
- エンティティの状態変更に必要なバリデーションを通過したかどうかがわからない。
ユースケースでバリデーションをしていますが、これは暗黙知的で、結局どのチェックを通過していればいいのかが分かりにくいのがペインでした。 つまりは、エンティティの状態変更と、ドメインサービスは密結合であるべきなのに、疎になってしまっているわけです。凝集度が低い状態ですね。
どうあって欲しいのか?
上記のペインを解消し、以下のような実装にしたいです。
これが実現できれば、凝集度高く応用の効くドメインサービスが作れそうです。
解決策: エンティティがドメインサービスのメッセージを期待すれば良い
悩んだ末、これだなと思ったのが「エンティティのメソッドの引数にドメインサービスからのメッセージを取れば良い」という方針です。 具体的な書き方を示します。大きく変わる箇所は二つ、エンティティのメソッドの引数と、ドメインサービスの返り値です。
まずは、ドメインサービスを以下のようにしてみます。
trait UserEmailUniqueChecker extends DomainService { import UserEmailUniqueChecker._ /** * メールアドレスがユニークなものであるか調べる * * @param email * 調べるメールアドレス * @return * 引数のメールアドレスがまだDBに同じものが存在せず、ユニークである時、[[Right]]で[[EmailIsUnique]]メッセージを返す */ def check(email: EmailAddress): Either[Because, EmailIsUnique] = Either.cond(isNotExist(email), new EmailIsUnique(email), EmailAlreadyExist) /** * 引数のメールアドレスを持つユーザーがまだDB上に存在しない * @param email * メールアドレス * @return * 存在する時: `false`, 存在しない時: `true` */ protected def isNotExist(email: EmailAddress): Boolean } object UserEmailUniqueChecker { /** * メールアドレスがユニークであることを示すメッセージ */ final class EmailIsUnique private[unique] (val email: EmailAddress) /** 失敗理由 **/ sealed trait Because /** メールアドレスがすでに使われていた **/ case object EmailAlreadyExist extends Because }
check メソッドのIFが以下のようになっています。この、EmailIsUnique がドメインサービスとエンティティを繋ぐメッセージです。
def check(email: EmailAddress): Either[Because, EmailIsUnique]
このメッセージはコンパニオンオブジェクトに以下のように定義されています。
object UserEmailUniqueChecker { /** * メールアドレスがユニークであることを示すメッセージ */ // コンストラクタがpackage private なので、パッケージが適切に切れていればよほどのことがなければドメインサービス以外からは生成できない // final なので継承もできないのでやはり他で誤って使われる確率が低い。 final class EmailIsUnique private[unique] (val email: EmailAddress) ... }
コメントに書いた通り、生成手段を絞っているので基本的にここでしか生成できないように作っています。つまり、この型の値を使うためにはこのドメインサービスを必ず経由する必要があるわけです。これで、一つ目のペインは解消されました。
次に User オブジェクトの changeEmail メソッドを見ていきましょう。
def changeEmail(message: EmailIsUnique): User = copy(email = message.email)
上記のようになっています。引数に先ほどのドメインサービスのメッセージを期待しています。この引数が何なのかを辿れば2つ目のペインが解消されます。また、このメッセージは上述した通り、ドメインサービスを経由しないと生成できないので、ドメインサービスを見落とすことがありません。
全体像
最後に
この実装アイデアはAkkaで有名なアクターモデルからのインスパイアです。アクター間でメッセージをやり取りし、メッセージによってアクターの状態が変わるのを見て、オブジェクト間でメッセージをしてあげるだけで良いということに思い当たりました。オブジェクト間のメッセージングをやるのにわざわざActorモデルのプログラミングをする必要はなく、オブジェクトが返すメッセージを定義してあげて、その生成可能箇所を制限してあげれば簡易的にやりたいことが実現できるな思い至り、今回の実装に至りました。
Rustの self, &self, &mut self の意味が分からなかったのでメモ
最近流行りのRust. システムよりのことを理解するのにGoよりは自分にあってそうと思い、たまに触ってます。
まだ基本的な文法が分からずメソッド引数の self, &self, &mut self の違いが分からなかったのでメモ。
fn method(self)・・・fn method(self: Self)の糖衣構文。インスタンスから所有権を奪ってしまう。使うシーンは稀で、メソッドがselfを何か別のものに変形し、変形後に呼び出し元が元のインスタンスを使用出来ないようにしたい場合に使用する。戻れない状態遷移の時に使えそう。fn method(&self)・・・fn method(self: &Self)の糖衣構文。所有権を取らず、借用する。普遍な借用。受け取った引数を変更せず参照のみ使いたいシーンで使う。普段Scalaで書いている時の挙動はこれが一番近い。fn method(&mut self)・・fn method(self: &mut Self)の糖衣構文。インスタンスの内部状態を変更したい場合に使う。